Spring Batch #1 - Get Started
스프링 배치 #1 - 시작하기
개요
이번 포스팅에서는 스프링 배치를 활용하여 배치 처리 애플리케이션을 개발하기에 앞서 스프링 배치가 무엇인지 기본적인 개념을 살펴보려고 한다.

배치(Batch)
배치란 사전적인 의미 그대로 무언가를 일괄적으로 처리함을 뜻한다. 개발자들 입장에서 보면 어딘가에 저장된 데이터를 일괄적으로 읽어 처리하고 어떠한 액션을 일괄적으로 수행하는 로직을 작성하는 것이 될 것이다.
일반적으로 배치 처리는 (일회성 배치도 있지만) 보통 일정한 주기로 반복 수행되는 특징이 있다. 특정 시점에 일괄로 수행되기 때문에 실시간 처리와는 개념이 다르다.
모든 것이 실시간으로 처리된다면 더 좋지 않은가? 하지만, 다음과 같이 실시간 처리보다는 배치 처리가 알맞은 워크로드는 분명히 존재한다.
- 정산 및 청구처럼 주기적으로 집계가 되어야 하는 경우
- 휴면계정 알림처럼 어떤 상태에 따라 일괄적으로 무언가를 수행해야 하는 경우
그리고 배치 처리는 실시간 처리에 비해 구현이 비교적 단순하며, 인프라 구성 또한 단순하다는 면에서 장점이 있다.
스프링 배치 vs 스파크
뜬금 없거나 전형 연관성이 없을 수 있지만 데이터를 가져와 처리하고 결과물을 만들어내는 관점에서 보면 스프링 배치와 스파크가 유사한 워크로드를 처리하지 않나 싶기도 하다. 물론, 본인은 스파크를 사용해본 적이 없다. 따라서, 인터넷 및 서적을 참고하여 얻은 스프링 배치와 스파크의 차이점을 다음과 같이 정리해봤다.
- 스프링 배치
- 워크로드를 처리하는 방식이 다른 일반 애플리케이션과 비슷하다. 즉, 일반 애플리케이션을 작성하는 것처럼 큰 이질감 없이 애플리케이션을 작성할 수 있다는 의미이다.
- 스프링 프레임워크를 사용할 수 있는 개발자는 굉장히 많은 편에 속한다. 그리고, 스프링 프레임워크를 사용할 수 있는 개발자라면 쉽게 접근할 수 있다.
- 스프링 배치를 사용하기 위해 복잡한 전용의 인프라를 구성할 필요가 없다.
- 상태관리 및 트랜잭션을 기본적으로 제공한다.
- 스파크
- 워크로드를 처리하는 방식이 일반 애플리케이션과는 다소 다르다. 주로 빅데이터 분석, 머신러닝 등에 특화되어 있다.
- 스프링 배치보다는 상대적으로 러닝커브가 있으며, 시장에서 능숙한 개발자를 찾기가 상대적으로 힘든 편이다.
- 분산 환경을 위해서는 복잡한 전용의 인프라 구성이 필요하다.
- 상태관리와 트랜잭션을 기본적으로 제공하지 않는다.
배치 프레임워크를 다양하게 사용해본 것은 아니지만, 스프링 배치만큼 배치 처리에 특화되어 잘 만들어진 프레임워크는 경험하지 못했다. 이제 스프링 배치가 무엇이고 어떤 구조로 구성되어 있는지 살펴보도록 하자.
특징
스프링 배치의 두드러진 특징은 다음과 같다.
- 상태를 관리해준다. 배치가 언제 시작되었고, 어느 스텝까지 수행되었고, 실패했는지 성공했는지 등을 관리해준다. 보통 복잡한 업무를 처리하는 경우 스텝이 수십개에 달하는 경우가 있다. 만약에 실패했다면 마지막으로 실패한 부분부터 다시 수행할 수 있다.
- 다양한 동시 처리 방법을 제공한다. 처리할 데이터가 많아진다면 동시 처리를 고민할 수 밖에 없다.
- 배치 특화이기 때문에 기본적으로 스케줄링을 지원하지 않는다. 스케줄링은 Quartz, Cron, Jenkins, Airflow 등을 활용할 수 있다.
배치 애플리케이션이 신경써야할 부분들은 프레임워크에서 기본 제공하고, 개발자는 애플리케이션 로직 구현만 집중하면 된다. 동시 처리 방법을 제공하기 때문에 처리할 데이터 규모에 따라 처리 방식을 다양화 할 수 있다.
구성요소
다음은 스프링 배치 애플리케이션을 작성할 때 흔히 보게 되는 요소들이다.
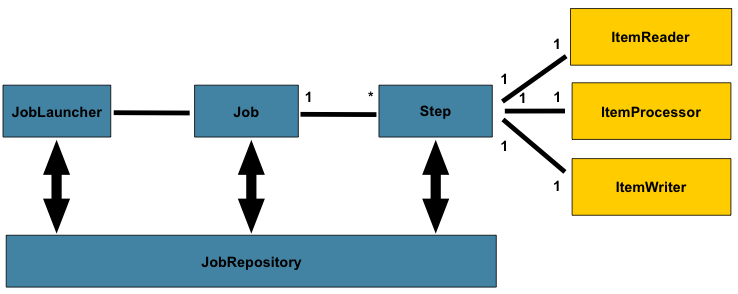
하나씩 설명하면 다음과 같다.
JobLauncherJob을 실행한다.
Job- 작업의 최상위 단위라고 보면 된다.
Job은 여러 하위Step들을 가질 수 있다.
- 작업의 최상위 단위라고 보면 된다.
Step- 말 그대로 어떤 작업을 처리함에 있어 수행하는 단계라고 보면 된다. 어떤 작업을 처리하는데 있어 단순한 경우에는 1단계만으로 충분할 수 있지만 복잡한 경우에는 수십단계에 이를 수도 있다.
ItemReader- 하나의
Step은 하나의ItemReader를 가질 수 있다. - 처리할 데이터를 읽어오는 부분이라고 보면 된다.
- 하나의
ItemProcessor- 하나의
Step은 하나의ItemProcessor를 가질 수 있다. - 처리 로직을 이곳에서 수행한다.
- 하나의
ItemWriter- 하나의
Step은 하나의ItemReader를 가질 수 있다. - 처리 결과물을 저장하는 등의 처리를 하는 곳이다.
- 하나의
JobRepository- 현재 수행되는 처리 작업에 대한 정보를 이 인터페이스를 통해 참조하고 업데이트한다.
하지만 이렇게 봐서는 선뜻 이해가 가지 않는다. 억지로 이해할 필요는 없고 지금은 그냥 이런 것들이 있구나 정도만으로도 괜찮다. 이해를 돕기 위해 실제 무언가를 처리하는 간단한 샘플 코드를 살펴보도록 하자.
샘플 코드
다음 샘플 코드는 코틀린으로 작성되었으며, 1부터 25까지의 수에 3을 곱하는 아주 단순한 예제이다. 구현 내용은 단순하지만 기본 구조는 다른 배치 애플리케이션을 작성하는 경우에도 크게 바뀌지 않기 때문에 잘 봐두기 바란다.
@Configuration
class SimpleJobConfig(
val jobBuilderFactory: JobBuilderFactory,
val stepBuilderFactory: StepBuilderFactory
) {
// Job 생성
@Bean
fun simpleJob(): Job = jobBuilderFactory.get("simpleJob")
.start(simpleStep())
.build()
// Step 생성
@Bean
fun simpleStep(): Step = stepBuilderFactory.get("simpleStep")
.chunk<Long, Long>(10) // 10개 단위로 write
.reader(reader())
.processor(processor())
.writer(writer())
.build()
val numbers = (1..25L).toMutableList()
// Reader 생성
fun reader(): ItemReader<Long> = ItemReader {
numbers.takeIf {
it.isNotEmpty()
}?.removeAt(0)?.also {
println("read: $it")
}
}
// Processor 생성
fun processor(): ItemProcessor<Long, Long> = ItemProcessor { item -> (item * 3) }
// Writer 생성
fun writer(): ItemWriter<Long> = ItemWriter { println("write: $it") }
}
실행 가능한 전체 코드는 여기 에서 클론할 수 있다. 그리고 클론받은 디렉터리로 이동해서 다음 명령을 실행하면 된다.
./gradlew clean :very-simple:test -i
위의 커맨드를 수행하면 다음과 같은 결과를 확인할 수 있다.
read: 1
read: 2
read: 3
read: 4
read: 5
read: 6
read: 7
read: 8
read: 9
read: 10
write: [3, 6, 9, 12, 15, 18, 21, 24, 27, 30]
read: 11
read: 12
read: 13
read: 14
read: 15
read: 16
read: 17
read: 18
read: 19
read: 20
write: [33, 36, 39, 42, 45, 48, 51, 54, 57, 60]
read: 21
read: 22
read: 23
read: 24
read: 25
write: [63, 66, 69, 72, 75]
출력에서 확인할 수 있는 것처럼, reader 에서 데이터를 읽어 processor 에서 처리하면 이것을 chunk 크기 만큼 모아놨다가 writer 에서 최종 처리하는 것을 확인할 수 있다. reader 는 null 을 만나면 읽기를 중단하고 chunk 중인 데이터를 모두 writer 가 처리한다음 Step 이 종료된다. 이를 도식화하면 다음과 같다.
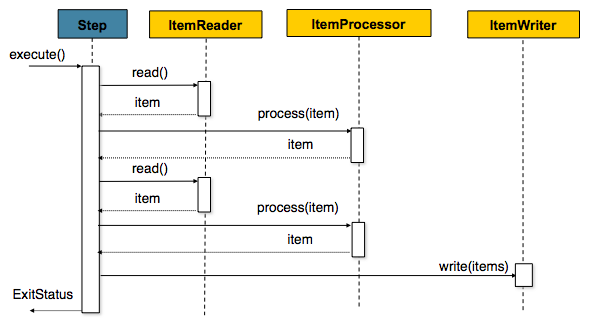
이렇게 데이터를 뽑아서 변형하고 로드하는 것을 ETL(Extract & Transform & Load)이라고 한다. 대부분의 배치 처리는 보통 이러한 ETL 의 연속으로 이루어진다.
마무리
다음 포스팅에서는 데이터베이스를 이용한 배치 처리를 살펴볼 것이다. 실제 업무에서도 데이터베이스를 이용한 배치 처리가 많다. 하지만 데이터베이스를 이용한 배치 처리는 신경써야할 부분들이 많다. 이러한 부분들에 대해서도 하나씩 살펴볼 것이다.