MySQL CDC With Debezium #3
디비지움으로 MySQL CDC 하기 #3
개요
이번 포스팅에서는 프로덕션에서 시스템을 구축하고 운영할 때 고려할 사항들을 살펴보려고 한다. 본인은 2020/04/09 ~ 2020/10/07 현재까지 장애를 총 1번 겪어봤다. 그것도 장애를 빠르게 인지했다면 처리가 매우 쉬웠을 장애였지만, 안타깝게도 모니터링 시스템이 경보를 제대로 전달해주지 못하는 바람에 처리에 다소 애를 먹었었다. 그래도 컨테이너 환경으로 만들어둔 덕에 불확실한 부분을 빠르게 테스트해보고, 대처할 수 있었다.
프로덕션 고려사항
프로덕션 환경에서는 장애가 발생했을 경우 어느 수준까지 장애가 용인이 되는지, 장애가 발생했을 경우 얼마나 빠르게 운영자(개발자)에게 전달이 되는지, 그리고 얼마나 빠르게 복구할 수 있는지가 중요하다. 또한, 처리 성능 역시 잘 나와야 한다.
따라서, 시스템을 구축할 때 다음 사항을 고려해야 한다.
- 가용성
- 카프카 브로커는 최소 3 대로 구성하는 것을 권장한다.
- 스키마 레지스트리의 경우 앞단에 LB 가 필요하다면 넣고 스케일아웃 하도록 한다.
- Zookeeper 는 최소 3 대로 구성하는 것을 권장한다.
- 성능
- 모두 JVM 기반 환경이므로 서버 하드웨어 선택과 GC 설정등 JVM 성능 관련 파라미터들을 잘 조정해야 한다.
- 필요하다면 서버의 커널 파라미터 설정도 할 필요가 있다.
- 카프카는 꽤 좋은 성능의 하드웨어를 사용해야 한다.
- 경보
- 모니터링 시스템이 있어야 하며, 로그나 지표에서 오류를 검출하여 담당자에게 이상 징후를 알릴 수 있어야 한다.
이 모든 것을 구성 및 관리하는 것은 쉬운 일이 아니다. 변경사항이 추적되지 않고, 빠르게 환경을 구성해 테스트해볼 수 없다면 장애 상황에서 검증이 어려워진다.
따라서, 도커와 같은 컨테이너 환경을 적극적으로 사용하길 권장한다. 컨테이너는 한번 구성된 환경이 불변성을 가지기 때문에 항상 같은 상태가 유지된다는 장점이 있다.
영속화가 필요한 데이터는 볼륨을 마운트해서 영속화하면 된다. 그리고, 개발, 스테이징, 프로덕션 환경 모두를 거의 동일하게 구성할 수 있으며, 쉘 스크립트, yaml 과
같이 텍스트 기반 설정으로 환경을 구성하기 때문에 git 과 같은 VCS 로 이력을 추적하기가 용이하다.
프로덕션 수준의 카프카 클러스터와 모니터링 시스템을 구성하는 내용은 별도의 포스팅을 통해 살펴 볼 것이다.
스냅샷
이전 포스팅에서도 설명했지만, 디비지움은 최초에 한번 스냅샷이라는 작업을 수행한다. 이 스냅샷이라는 작업은 원본 테이블의 데이터를 모두 읽어 토픽에 행 단위로 프로듀싱 하는 작업이다. 수행속도는 나쁘지 않다. 스냅샷 로직 내부에서 데이터 건수에 따라 건수가 적으면 페이징 방식으로 읽어 처리하고, 많을 경우 커서 방식으로 읽어 처리한다. 이처럼 기본으로 제공하는 기능을 사용할 수도 있고, ETL 애플리케이션을 별도로 만들어 스냅샷을 수동으로 수행할 수도 있다.
ETL 애플리케이션을 통해 수동으로 스냅샷을 수행하는 경우라면 디비지움의 테이블 토픽에 CDC 이벤트가 계속해서 기록되므로, ETL 애플리케이션을 모두 수행한 다음에 이러한 CDC 이벤트를 컨슘하는 것이 좋다. 이벤츄얼 컨시스턴시(Eventual consistency) 개념으로, 변경 데이터가 순차적으로 반영되면 어느 시점이 되어 데이터가 원본과 같아지게 된다. 컨슘을 하면서 ETL 을 함께 수행한다면 데이터 일관성을 보장할 수 없다.
어느 방식이 더 낫다고 단정 짓기 힘들지만, 유연성을 따져보면 ETL 애플리케이션을 별도 작성하는 것이 더 나아보인다. 즉, 별도로 작성하면 중간에 어떤 문제가 발생해도 다른 애플리케이션에 영향을 주지 않고 개별 대처가 훨씬 쉽다는 것이다. 이렇게 해서 다른 MySQL 데이터베이스로 3시간 동안 1억 4천만 건을 스냅샷 수행한 경험이 있다. 이 1억 4천만건은 단순히 한 테이블에서 다른 테이블로의 동일한 데이터 이동이 아니라 역정규화가 이뤄진 형태의 스냅샷이었다. 물론 이렇게 하면 컨슈머 애플리케이션과 ETL 애플리케이션 사이의 코드 중복이 어느정도 발생하게 되는건 사실이다.
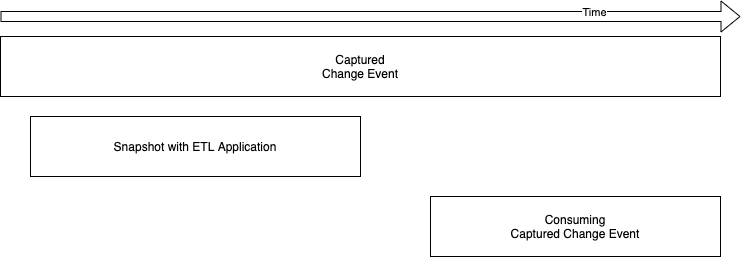
스냅샷 과정은 초기에 한번 수행하는 프로세스이지만, 원본과 대상의 데이터 일관성을 맞추는 굉장히 중요한 과정이기도 하다. 테스트해보고, 고민해보고 운영 방식에 걸맞는 방식을 선택하는 것이 좋다.
원본 데이터베이스 변경이 필요한 경우
운영을 하다보면 바라보는 원본 데이터베이스를 변경해야 하는 경우가 종종 생기게 된다. 보통 사유는 다음과 같다.
- 하드웨어 증설
- 대량의 데이터가 존재하는 테이블에 컬럼을 추가하거나 변경하는 스키마 변경
- 복구 불가능한 데이터베이스 장애
보통 위와 같은 상황에서는 대상이 되는 데이터베이스 서버를 서비스에서 제외한 다음 대응하게 된다. 데이터베이스를 오랫동안 사용할 수 없는 상황이 되기 때문에 디비지움 커넥터를 예비 데이터베이스로 연결을 해줘야 한다. 문제는 여기에서 생기는데 단순히 커넥터 설정에 있는 데이터베이스 설정만 바꿔서는 안된다. 각각의 데이터베이스가 만들어내는 binlog 는 이름도 다르고 포지션도 다르기 때문에 문제가 발생하게 된다.
1번과 2번의 경우에는 활성 장비와 예비 장비가 모두 살아 있는 상태에서 사전에 대응하므로 커넥터를 아예 새로 만들고, 기존 커넥터를 폐기하는 방식으로 대응하면 된다.
커넥터 구성을 새로 구성하는 방법은 다음과 같다. 다음과 같은 원본 커넥터 설정 mysql-connect-db1.json 이 있다고 가정해보자.
{
"name": "mysql-connector-db1",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"database.hostname": "mysql-master-db1",
"database.port": "3306",
"database.user": "cdc_user",
"database.password": "1234",
"database.server.id": "3141592",
"database.serverTimezone": "Asia/Seoul",
"database.server.name": "cdc_db1",
"database.history.kafka.bootstrap.servers": "kafka-1:9092",
"database.history.kafka.topic": "dbhistory.db1",
"include.schema.changes": "true",
"table.whitelist": "sample.tb_user"
}
}
다음과 같이 변경한 다음 설정파일을 저장한다.
{
"name": "mysql-connector-db1-2020100700",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"database.hostname": "mysql-master-db1",
"database.port": "3306",
"database.user": "cdc_user",
"database.password": "1234",
"database.server.id": "3141592",
"database.serverTimezone": "Asia/Seoul",
"database.server.name": "cdc_db1",
"database.history.kafka.bootstrap.servers": "kafka-1:9092",
"database.history.kafka.topic": "dbhistory.db1.2020100700",
"include.schema.changes": "true",
"table.whitelist": "sample.tb_user"
}
}
그런다음 다음과 같이 새로운 디비지움 커넥터를 생성한다.
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" \
http://127.0.0.1:8083/connectors/ -d @mysql-connect-db1.json
그리고, 데이터가 잘 인입되는지 확인 후 기존 커넥터를 삭제하면 된다.
curl -i -X DELETE -H "Accept:application/json" -H "Content-Type:application/json" \
http://127.0.0.1:8083/connectors/mysql-connector-db1
이렇게 하게 될 경우 문제점은 중복 프로듀싱이다. 따라서 메시지가 중복 프로듀싱 되더라도 문제없이 처리되도록 설계하는 것이 좋다.
반면, 3번의 경우에는 복구 불가능한 장애 상황에서 예비로 변경하는 것이기 때문에 활성 장비에서 기록된 binlog 포지션이 예비 장비의 binlog 포지션 어느 부분에 해당하는지 확인한다음 binlog 포지션을 변경해줘야 한다. 다소 번거러운 작업이다. 하지만 binlog 포지션만 정확히 찾을 수 있다면 데이터 유실은 걱정할 필요가 없다.
빈로그 포지션을 변경하는 방법은 다음과 같다. 먼저 디비지움 커넥터의 마지막 포지션이 담긴 파티션의 내용을 확인해야 한다.
sudo docker run -it --rm edenhill/kafkacat:1.5.0 -b {Server list. e.g. kafka-1:9092} -C -t \
{Name of the offset topic} -f 'Partition(%p) %k %s\n'
커넥터 이름을 확인한 다음 제일 마지막 오프셋 내용을 통째로 복사한다. 내용은 다음과 유사할 것이다.
Partition(10) ["mysql-connector-test-db",{"server":"cdc_test_db"}] {"ts_sec":1600149140,"file":"test-bin.000638","pos":8579523,"row":1,"server_id":1001241,"event":2}
그런 다음 mysqlbinlog 를 이용해 원격 서버의 binlog 포지션을 조사해야 한다.
sudo docker run -it --rm mysql mysqlbinlog -h{Server host} -u{User ID} -p --read-from-remote-server \
--start-position=8579523 --stop-position=8679523 test-bin.000638
변경할 적당한 포지션을 찾았다면 해당 포지션으로 건너뛸 수 있도록 다음과 같이 토픽에 내용을 프로듀싱해주면 된다. 만약 858952 포지션으로 강제 적용해야 한다면 다음과 같이 할 수 있다.
echo '["mysql-connector-test-db",{"server":"cdc_test_db"}]|{"ts_sec":1600149140,"file":"test-bin.000638","pos":858952,"row":1,"server_id":1001241,"event":2}' | \
docker run -i -a stdin --rm edenhill/kafkacat:1.5.0 -P -b {Server list. e.g. kafka-1:9092} -t {Name of the offset topic} \
-K \| -p {Partition number. 10 in this case.}
파이프를 사용하기 때문에 sudo 권한이 필요하다면 sudo su 로 권한을 상승시켜 실행하거나 스크립트로 만들어 실행하기 바란다.
프로덕션용 데이터베이스는 아예 활성 장비와 예비 장비 두 대를 한 번에 준비하는 것이 좋다. 준비라고 해봤자 권한 추가하는 것과 이력을 관리하는 것 밖에 없으므로 큰 노력이 들지 않는다.
디비지움 SQL 파서 오류
디비지움은 앤틀러(Antlr)를 이용해 SQL 파서를 직접 만들었다고 한다. 기존의 파서가 MySQL 버전마다의 다양한 DDL 을 제대로 파싱하지 못한 것이 주요 이유였는데, 현재의 파서도 그런 문제가 있는 것으로 보인다. 하지만 이 부분은 확실치 않다. 어쩌면 5.5 버전의 DDL 을 파싱하지 못하는 것이 아닌가 추측이 들기도 한다. 디비지움에서 공식으로 지원하는 버전은 5.7 부터이기 때문이다. 본인은 필요에 의해 5.5 버전을 지원할 수 있도록 살짝 패치를 해서 사용하고 있는데, 공교롭게도 5.5 버전의 데이터베이스에서 수행한 DDL 이 장애를 만들었다.
아무튼 이런 상황이면, 커넥터에서 오류가 발생한 데이터베이스 스레드만 중단된다. 아무리 재시작을 해도 정상화되지 않으므로, 마지막 binlog 포지션을 기점으로 오류가 발생하는 지점의 포지션을 확인해야 한다. 그런 다음 필요하다면 해당 포지션을 건너뛸 수 있도록 만들어 줘야 한다. 단순히 포지션을 변경하는 수준이라면 아주 쉽게 처리할 수 있다.
마무리
이번 포스팅까지 디비지움에 대한 대부분을 살펴보았다. 빠진 부분이 있거나, 추가가 필요한 내용은 업데이트 하거나 별도의 포스팅을 할 예정이다.