MySQL CDC With Debezium #1
디비지움으로 MySQL CDC 하기 #1
개요
MySQL 테이블의 특정 칼럼 값이 변경될 때 해당 로우(row)의 데이터 또는 그와 연관된 정보가 준실시간으로 필요해졌다. 몇 가지 방식을 생각해 볼 수 있는데, 서로 장단점을 따져보니 CDC(Change Data Capture)가 가지는 장점이 더 많았다.
이 문서는 CDC 가 어떤 장점을 가지는지, 기술 대중성이 있는지를 파악함에 목적이 있다.
고민

다음의 고민들이 있다.
- B 서비스에서는 A 서비스가 소유한 데이터베이스의 데이터가 필요하다.
- API 호출로 A 서버스로의 데이터 조회가 가능하지만, B 서비스는 전체적으로 이러한 정보 조회가 굉장히 빈번하기 때문에 대량의 API 호출을 유발한다.
- B 서비스에서는 A 서비스가 소유한 데이터베이스에서 데이터를 가져와야 하지만, A 서비스의 데이터베이스가 소유한 데이터를 제외하고 가져와야 한다.
- 하나의 물리적 데이터베이스라면 LEFT 조인을 하면 되는 상황이지만, 불가능하다.
- 이러한 연산을 API 에서 처리하기에는 너무 느리다.
- A 서비스가 어느 정도의 호출을 감당할 수 있는지 장담할 수 없다.
결론을 얘기하자면, 마이크로서비스 아키텍처에서 각자의 도메인이 소유한 데이터외에 타 도메인의 데이터도 필요한 상황이 생긴다. 하지만, 서비스들 사이의 데이터 조회를 위해 API 를 호출하는 방식은 너무 느리고(모든 API 가 캐싱된 정보를 돌려준다면 모르겠지만), 성능적인 영향이 있는지 없는지 확인해야 할 지점이 생기게 된다. 이 과정이 실제 업무에서는 굉장한 스트레스이다. 다른 서비스에 미칠 성능 영향을 유관부서 담장자들과 커뮤니케이션해야 하고, 개선해야 될 것이 있다면 그에 대응해야 하고, 성능 문제가 없을 것이라 예상했지만 프로덕션 서비스를 시작했을 때 문제가 터지면 그때서야 부랴부랴 서버를 더 투입한다. 그렇게 해서 성능이 안정되면 다행이지만, 또 다른 서비스가 동일한 문제를 만들지 않으리란 법은 없다.
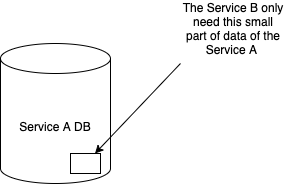
B 서비스에서 필요한 정보는 A 서비스가 가지는 정보의 극히 일부이다. 그게 아니라면 도메인의 대부분이 겹친다는 것이므로 B 서비스와 A 서비스는 합치는 걸 고려해 봐야 할 것이다. 극히 일부의 필요한 데이터를 B 서비스가 소유한 데이터베이스에 실시간 반영할 수 있다면, 모든 데이터를 SQL 쿼리로 조회할 수 있기 때문에 고민 거리가 많이 줄어들게 된다. 데이터는 알아서 배달이 될 것이고, 오로지 서비스 개발자의 오너쉽 도메인만 신경쓰면 된다.
전통적인 방식
몇 가지 전통적인 방식중 가장 많이 사용하는 방식은 데이터 변경 행위가 일어날 때마다 이벤트를 발생시켜주는 것이다.
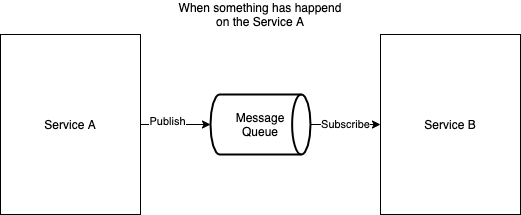
하지만 이 경우에는 다음과 같은 잠재적인 문제가 존재한다.
- 운영, 버그 등의 이슈로 데이터베이스 데이터를 직접 변경해야 하는 경우, 이벤트가 누락될 수 있다. 물론, 이벤트를 수동으로 발생시킬 수도 있겠지만, 변경이 일어난 대상을 특정하기 어렵다면 얘기는 달라진다.
- 데이터 변경 행위에 대한 이벤트를 발생시키기 위해 추가적인 코드가 필요하다. 데이터 변경이 단일 애플리케이션이나 서비스에서만 일어난다면 코드를 추가하는 것이 어렵지 않겠지만, 그렇지 않다면 코드 추가는 다소 부담스러워진다. 레거시 시스템들은 대부분 이런 부분에 있어 파악이 어렵거나 코드 추가가 어려운 경우가 많다.
- 애플리케이션 버그 및 이벤트 스토어 장애에 의해 이벤트가 누락될 수 있다.
그 외에 배치, 리플리케이션 데이터베이스를 사용하는 방법도 있겠으나, 배치는 실시간 처리가 힘들고, 서로 다른 서비스가 서로 다른 도메인의 전체 데이터베이스를 참조하는 것은 좋은 디자인이라고 볼 수 없다. 서비스는 각자 독립적으로 성장할 수 있어야 하고 최대한 느슨한 결합을 가지는 것이 좋다.
CDC(CHANGE DATA CAPTURE)
CDC 는 변경 데이터 포착(Change Data Capture)이다. 주로 데이터베이스같은 데이터 스토어의 데이터 변경을 포착하여 ETL, 감사(audit), 캐싱과 같은 다양한 후속 처리를 하는 데 사용된다.
본인은 MySQL 데이터베이스를 주로 사용하기 때문에 MySQL CDC 솔루션들을 찾아봤다.
https://github.com/wushujames/mysql-cdc-projects/wiki
대충 훑어보면 플립카트, 링크드인, 알리바바등이 내부적으로 CDC를 사용하고 있는 것으로 보인다.
플립카트의 경우:
Data change propagation from source to consumers is a fairly common requirement in systems that automate business processes. An example is inventory updates on a warehousing system reflecting on product pages of an eCommerce portal.
원천에서 컨슈머로의 데이터 변경 전파는 비지니스 프로세스를 자동화하는 시스템에서 상당히 일반적인 요구사항이다. 이커머스 포탈의 프로덕트 페이지에 반영되는 웨어하우징 시스템의 재고 업데이트가 그 예이다.
링크드인의 경우:
We have built Databus, a source-agnostic distributed change data capture system, which is an integral part of LinkedIn’s data processing pipeline.
우리는 소스에 구애받지 않는 분산 변경 데이터 포착 시스템인 Databus를 만들었으며, 이는 LinkedIn의 데이터 처리 파이프 라인에 없어서는 안될 부분이다.
국내의 경우 카카오뱅크, 카카오커머스, 라인커머스가 CDC 를 사용하고 있다.
여러 솔루션들 중 Kafka와 가장 궁합이 잘 맞을 것으로 판단되는 디비지움(Debezium)을 선택했다.
DEBEZIUM
디비지움은 CDC 를 수행하기 위한 오픈소스 분산 플랫폼이다.
여기 블로그에 가보면 왜 CDC 인가? 라는 내용이 다음과 같이 설명되어 있다.
Finally, CDC can also play a vital role in microservices architectures; exchanging data between services and keeping local views of data owned by other services achieves a higher independence, without having to rely on synchronous API calls.
마지막으로 CDC는 마이크로 서비스 아키텍처에서 중요한 역할을 수행할 수 있다. 서비스 사이에서 데이터를 교환하고 다른 서비스가 소유한 데이터의 로컬 뷰를 유지하면 동기식 API 호출에 의존하지 않고도 독립성이 높아진다.
중요한 내용이다. 마이크로서비스 아키텍처에서는 서비스들 사이의 데이터 조회가 이러한 동기식 API에 의존하는 경우가 많은데, 이 부분에서 챌린지가 빈번하게 발생하고, 장애로 이어지는 경우가 많다.
디비지움을 사용하는 일반적인 아키텍처 구성은 다음과 같다.
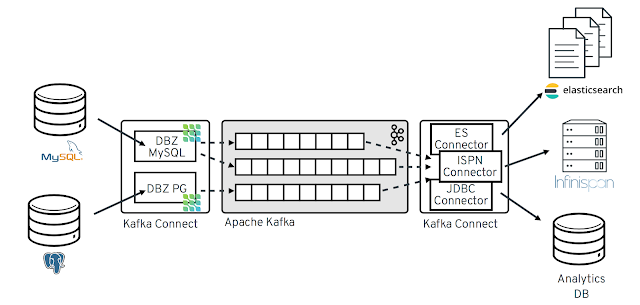
위 그림에서 DBZ XXX Kafka Connect에 해당하는 부분이 디비지움에 해당하는 부분으로, 데이터베이스의 데이터 변경을 포착하여 Kafka 에 이벤트를 푸시하고, 특정 이벤트에 관심을 가지는 서비스들이 소비하는 구조이다.
특징 및 제약조건은 다음과 같다.
- MySQL 외에도 PostgreSql, Mongo 등을 지원한다.
- 스키마 변경, INSERT, UPDATE, DELETE 모두 변경 포착이 가능하다.
- MySQL Replication Slave 처럼 작동한다.
- 디비지움을 재시작하면 마지막에 중단된 로그 포지션부터 데이터 변경 포착을 시작한다. 즉, 유실되지 않는다.
- MySQL 관련
- log-bin 이 설정되어 있어야 한다.
- MySQL Slave 에 log-bin 을 설정해놨을 경우 해당 Slave 에 붙어서 CDC 를 할 수 있다.
- 이런 구성으로 CDC 를 할 경우 MySQL 서버 설정에 log_slave_update=1 설정이 반드시 필요하다. 그렇지 않을 경우 Replication 으로 인한 변경분은 binlog 에 남지 않게 된다.
- binlog_format=row
- binlog_row_image=full
- MySQL 5.6 이상부터 지원한다.
- MySQL 5.5 는 명시적인 내용이 없으나, full 로 봐도 무방하다. 오래된 오피셜 문서를 통해 확인한 내용이다.
디비지움은 기본적으로 5.5를 지원하지 않지만, 몇 줄의 소스코드 수정을 통해 5.5를 사용할 수는 있다.
이러한 구성이 가지는 장점은 명확하다.
- 이벤트 발생을 위한 추가적인 코드가 애플리케이션 서비스에 필요하지 않다. 즉, 능동적으로 데이터 변경을 포착할 수 있다.
- 리플리케이션 로그 포지션을 잃어버리지 않는 한 이벤트 누락이 발생하는 일은 없다.
- 다른 서비스에 대한 데이터베이스 의존성을 완화할 수 있다.
마무리
MySQL 데이터베이스를 사용하고 위에서 언급한 내용들에 대해 고민해본적이 있다면 추천하는 설루션이다. 실제로 프로덕션에 적용해서 서비스의 비효율적인 부분들을 많이 개선했다. 디비지움 프로젝트도 현재 MySQL 에 대해서는 성숙도가 높다.