Kafka Basics
카프카 시작하기
개요
이번 포스팅에서는 카프카의 기본 개념부터 시작해서 샘플 구성을 살펴보려고 한다.

카프카
카프카는 메시징 큐이다. 디스크에 메시지를 저장하며, 컨슘한 메시지는 삭제되지 않고 보존 기한만큼 보존된다. 프로듀싱한 메시지는 클러스터 내에 지정한 개수만큼의 사본으로 저장되어, 서버 장애에도 고가용성을 달성할 수가 있다. 또한, 확장성과 처리 성능이 좋다. 모던 아키텍처에서는 리얼타임 이벤트 처리를 위해 카프카와 같은 메시징 큐를 아키텍처에 포함하는 경우가 많다.
기본 개념들
카프카를 사용하면서 주로 알고 있어야 하는 개념은 다음과 같다. 복잡한 설명없이 핵심만 추려서 나열했다.
- 브로커
- 하나의 카프카 서버를 의미한다.
- 이런 브로커들을 묶어 카프카 클러스터를 만들게 된다.
- 최소 3 대 이상이 무난하다.
- 브로커를 쉽게 스케일아웃할 수 있다.
- 토픽
- 토픽은 프로듀싱한 메시지가 담기는 통 쯤으로 생각하면 된다.
- 메시지
- 메시지는 키와 값, 헤더로 구성된다.
- 파티션
- 토픽 내부에서 메시지가 담기는 구획 구간이다.
- 메시지가 어느 구획에 담길지는 메시지 키에 의해 결정되며, 동일한 메시지 키를 가진 메시지는 항상 같은 파티션으로 담긴다.
- 키가
NULL이라면 랜덤하게 배분된다. - 파티션의 수는 운영중에 늘릴 수 있지만 줄일 수는 없다. 초기에 파티션 수를 신중하게 결정하고, 운영중에 파티션 수를 늘려야 한다면 신중하게 결정해야 한다.
- 읽기와 쓰기 작업은 리더 파티션에만 수행되며, 팔로워 파티션은 리더 파티션으로부터 복제만 하게 된다.
- 리플리케이션 팩터(RF)
- 복제량으로, 클러스터 내에 몇 개의 사본이 존재하는지이다.
- 이 값을 3 으로 한다면 카프카 클러스터내에 원본 메시지 포함 총 3 개의 메시지 사본이 존재하게 된다.
- 이 값은 브로커 수 이하여야 한다. 2 ~ 3 정도로 설정하는 것이 무난하다.
- 최소 사본
- 메시지를 프로듀싱할 때 최소 몇 개의 사본이 존재할 때 프로듀싱을 성공한 것으로 보는지이다.
- 프로듀서의
acks설정이 -1(all) 인 경우에 유효하다. - 이 값은 RF 값 이하로 설정해야 프로듀싱 오류가 발생하지 않는다. 예상치 못한 브로커의 셧다운을 고려해서 RF + (-1 ~ -2) 정도로 설정하는 것이 좋다.
- 브로커 설정 지정자는
min.insync.replicas이며, 기본값은 1 이다.
- 프로듀서
- 토픽에 메시지를 프로듀싱하는 주체이다.
- 펍섭(Pub-Sub) 모델에서 퍼블리셔(Publisher)에 해당한다.
acks는 메시지를 프로듀싱할 때 메시지가 전달된 여부를 확인하는 수준이다. 비즈니스 요구사항에 맞게 선택하면 된다.0: 리더가 제대로 메시지를 전달받았는지 확인하지 않는다. 그만큼 빠르지만 유실 가능성이 가장 크다.1(기본): 리더가 제대로 메시지를 전달받았는지 확인한다.0보다는 느리지만 유실 가능성은 거의 없다. 하지만 리더가 메시지를 받은 다음 장애로 복구 불가한 상태가 되면 여전히 유실될 가능성이 존재한다.-1: 리더 뿐만 아니라 팔로워에도 복제되었는지 확인한다. 가장 느리지만 유실 가능성은 없다.
- 컨슈머
- 토픽에서 메시지를 컨슘하는 주체이다.
- 하나의 컨슈머는 서로 다른 토픽 하나씩을 컨슘할 수 있다.
- 펍섭(Pub-Sub) 모델에서 섭스크라이버(Subscriber)에 해당한다.
- 컨슈머 그룹
- 컨슈머는 컨슈머 그룹으로 묶을 수 있다.
- 같은 컨슈머 그룹에 속한 컨슈머는 코디네이터에 의해 각기 다른 파티션을 컨슘하게 된다. 즉, 하나의 파티션은 동일한 컨슈머 그룹에서 하나의 컨슈머에 의해서만 컨슘된다.
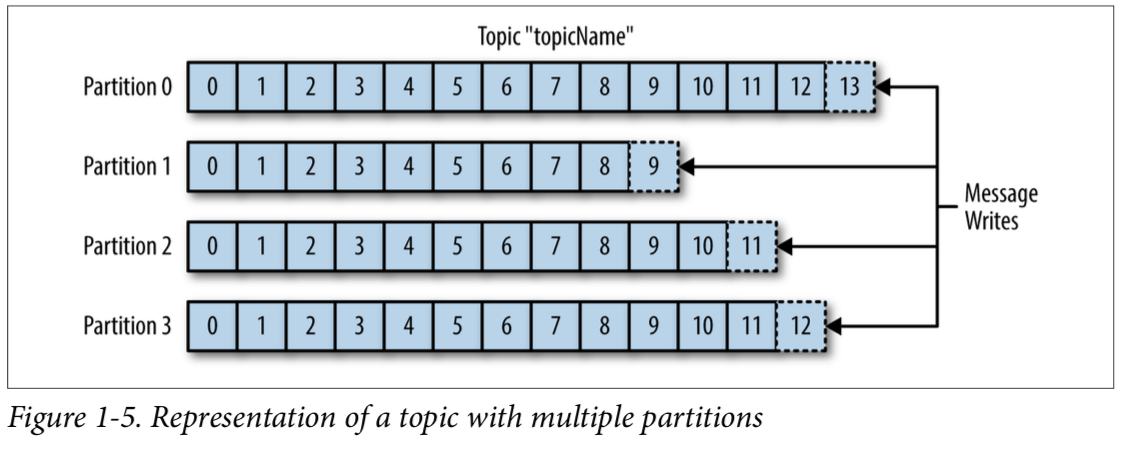
다음은 토픽과 파티션에 대한 이해를 돕기 위한 그림이다.
다음은 컨슈머 그룹의 컨슈머가 토픽내에 있는 파티션을 어떻게 컨슘하는지 이해를 돕기 위한 그림이다.

위의 그림에서 컨슈머 1 이 없어진다면 어떻게 될까? 그렇게 되면 컨슈머 0 이나 2 가 컨슈머 1 을 대신해서 파티션을 컨슘하게 된다. 다시 컨슈머 1 이 살아난다면 컨슈머 0 과 2 가 컨슘하던 파티션중 일부를 컨슘하게 된다.
샘플 클러스터
다음은 샘플 클러스터 구성이다. 다음과 같이 클론 받아서 실행하면 된다.
git clone https://github.com/m0rph2us/docker-kafka
cd docker-kafka
sh setup-network.sh
docker-compose up -d
이 샘플 클러스터는 CMAK 라는 관리도구를 함께 포함하고 있다. 접속과 클러스터 모니터링 초기화하는 README 에 잘 설명되어 있으므로 참고하여 확인해보기 바란다.
토픽은 앞서 얘기한 CMAK 로 생성할 수 있지만, 다음과 같이 커맨드라인을 사용하여 토픽을 생성할 수도 있다.
docker-compose exec kafka-1 /kafka/bin/kafka-topics.sh \
--create --bootstrap-server kafka-1:9092 \
--replication-factor 3 --partitions 1 --topic test_topic
만들어진 토픽은 다음과 같이 확인할 수 있다.
docker-compose exec kafka-1 /kafka/bin/kafka-topics.sh \
--describe --zookeeper zookeeper-1:2181/kafka \
--topic test_topic
다음과 같이 커맨드라인으로 프로듀싱을 해볼 수 있다.
docker-compose exec kafka-1 bash -c "echo 'test' | /kafka/bin/kafka-console-producer.sh \\
--broker-list kafka-1:9092 \\
--topic test_topic"
다음과 같이 커맨드라인으로 컨슈밍을 해서 확인할 수 있다.
docker-compose exec kafka-1 /kafka/bin/kafka-console-consumer.sh \
--bootstrap-server kafka-1:9092 \
--from-beginning \
--property print.key=true \
--topic test_topic
이번 포스팅에서는 여기까지만 살펴보기로 한다.
마무리
이번 포스팅에서는 카프카에 대해 간략히 살펴보았다. 기본적인 내용이지만 가장 핵심인 내용이기도 하다. 추가적인 내용과 활용 예제는 별도의 포스팅으로 다룰 것이다.